web前端优化–其一
web前端是一门神奇的技术。我们编写html标记和css语言,屏幕上就会显示出漂亮的页面。
但浏览器到底是如何使用我们的 HTML、CSS 和 JavaScript 在屏幕上渲染像素的呢?
一张最简单的网页
<html lang="en">
<head>
<meta charset="UTF-8">
<title>hello word</title>
</head>
<body>
hello word
</body>
</html>
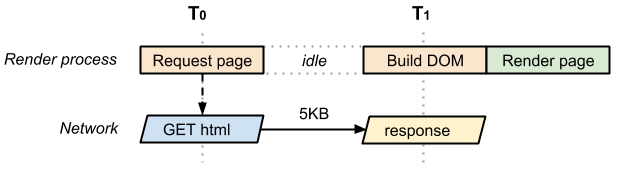
当我们在浏览器里输入网址敲回车,浏览器就会去获取我们的html文件,在接收到服务器返回的内容之后就开始构建 dom(document object model),然后渲染页面到浏览器上。似乎很简单,事实上也很简单。(如下图示)
如果加上一个css
<html lang="en">
<head>
<meta charset="UTF-8">
<title>hello word</title>
<link rel="stylesheet" type="text/css" href="a.css">
</head>
<body>
hello word
</body>
</html>
事实上,我们的网站可能还有一些css。当我们加上这些css之后,渲染过程又会发生变化呢?
浏览器获取html文件后开始一步步构建dom,解析过程中发现了link标记并发起了下载请求,然后继续构建dom。我们的html标识很少,所以很快就会构建完成。 此时,我们的css文件可能并没有下载完成,那么浏览器就不得不等待css的下载完成。在我们的css下载完成后,浏览器用css生成 cssom。最后再将dom 和 cssom 合成 渲染到浏览器。
好像变得稍微复杂了一点?浏览器渲染需要dom 和 cssom, css又需要下载和解析。在此这前浏览器都会是一片空白。需要强调的一点是虽然渲染dom、cssom是必须的,但是dom的构建是可以逐步的,而cssom却必须要全部构建完成才可以参与渲染。(过程如下图)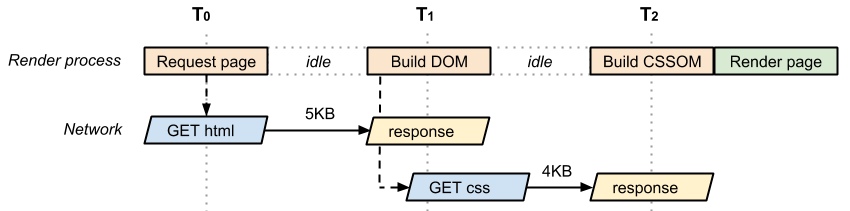
再加上js呢?
那么,我们再给这个网页加一个js文件吧,我们的网页越来越完整了。我们的浏览器又一次获取到了html,又一次勤勤勉勉的构建dom,又一次发现了link标记并发起了下载,又一次勤勤勉勉的继续构建,他发现了script标签。
浏览器暂停了构建dom,并发起了 同步 下载请求并准备执行。但是在执行js之前,我们的css还没有下载完成,我们必须先等css下载解析完成才能继续执行js。因为浏览器不知道js是否会操作css,必须等到cssom构建完成。等到js下载完成并执行完毕,浏览器继续构建dom,直到完成。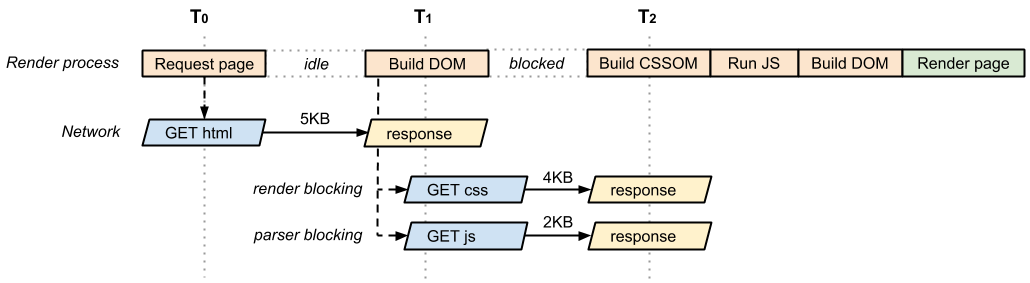
还会不会更复杂?
可是我们的页面上往往会有多个js(如下图).当我们解析到第一个script的时候,浏览器阻止构建dom,并发起同步请求并下载a.js。等到a.js下载完成并执行完毕,浏览器发起b.js的下载请求,并执行b.js,再继续构建dom。
这种处理方式很明显的效率并不好。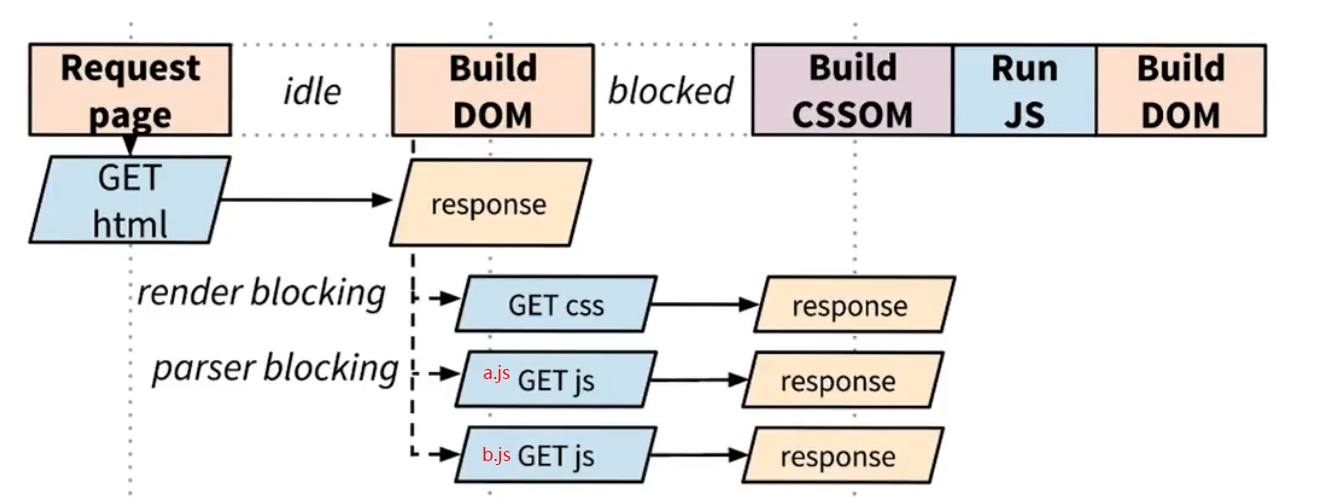
预加载扫描器
还好,现代浏览器有一个特殊浏览,叫预加载扫描器(详见)。当浏览器被脚本阻塞时,第二个轻量级分析器会扫描剩余的标记以查找其他资源并发起下载,例如样式表,脚本,图像等。目的是当主HTML解析器到达它们时,它们可能已经被下载并且因此在页面中稍后减少阻塞。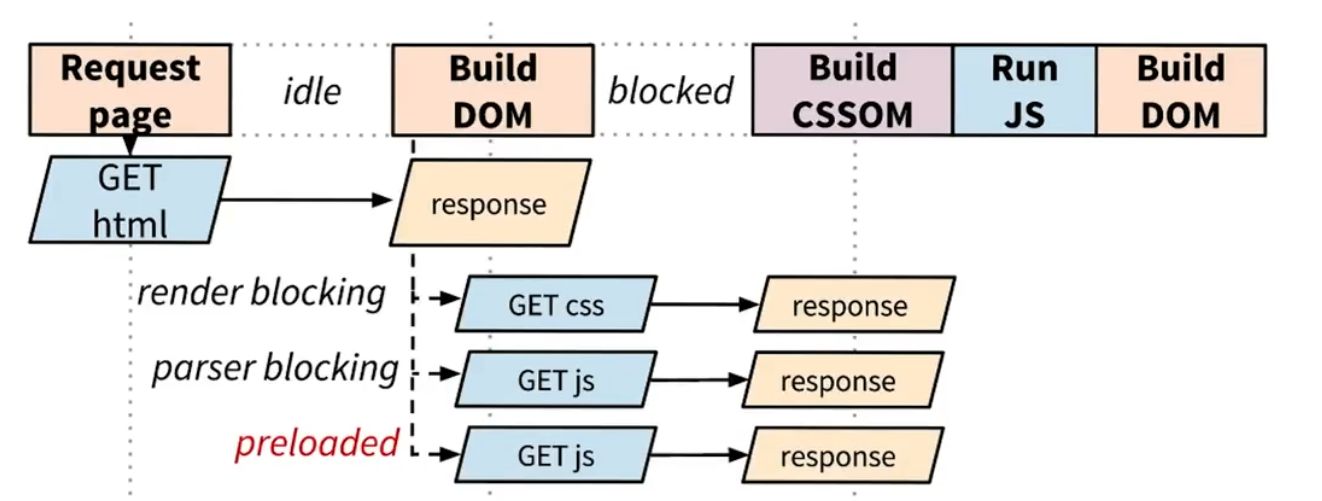
http协议怎么说?
在不同的http协议版本中,我们下载文件的方式可能还会有点不一样。
- 在http1.0及之前,每一个http请求会打开一个tcp/ip连接,并且只有等上一个http请求处理完成之后才会处理下一步http请求。
- 在http1.1时代引入了管道概念,tcp/ip连接可以被复用,一个tcp/ip可以处理多个http请求。但是,服务器依然只会在处理完成上一个Http请求之后才处理下一个http请求。
- http2时代一个域名只有一个tcp/ip连接,使用数据库传输,大大掉升了性能(详见)
最后
最后我们来总结一下。
- 浏览器渲染需要dom 和cssom
- dom可以逐步构建,但是cssom只能一次性完全构建完成才可以,所以尽快构建cssom是快速显示网页的关键。
- cssom的构建会阻止js的执行(js的执行需要cssom先构建完成),js又会阻止dom的构建。